Titanic Kaggle Prediction With RapidMiner
This is a walk through the steps to produce a decision tree model in RapidMiner Studio that will generate a prediction submission for the Kaggle Titanic challenge. RapidMiner is a data science platform with its core being open sourced (RapidMiner GitHub Repo)
Training Data Exploration
Download both the train.csv and test.csv data from the Kaggle Titanic competition page. Import the training dataset into RapidMiner by clicking the “+ Import Data” button in the Repository tab. Accept all defaults, we’ll override some elements via operator chaining.
Next lets generate a correlation matrix in order to see which attributes we should keep and which we should dispense with.
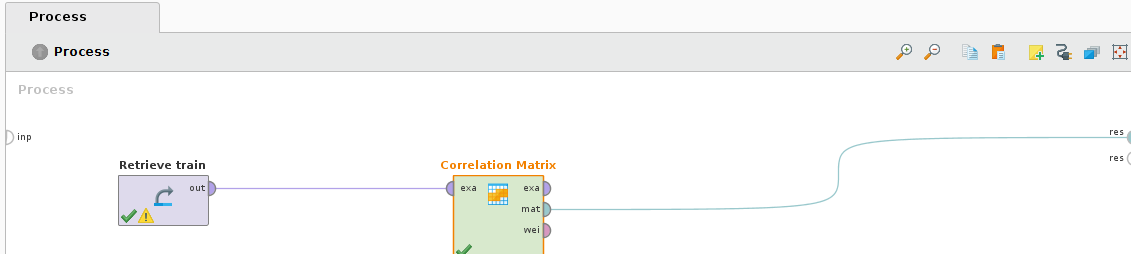
Drag the training dataset from the repository tab to the design view’s process tab. Then in the Operators tab search for “correlation” and drag the Correlation Matrix into the process tab. Connect the training dataset output “out” node to the correlation matrix “exa” input node. Then the “mat” correlation matrix output node to the “res” node on the furthest right hand side of the process tab.
Then click the play button. The correlation matrix is displayed in the Results view.
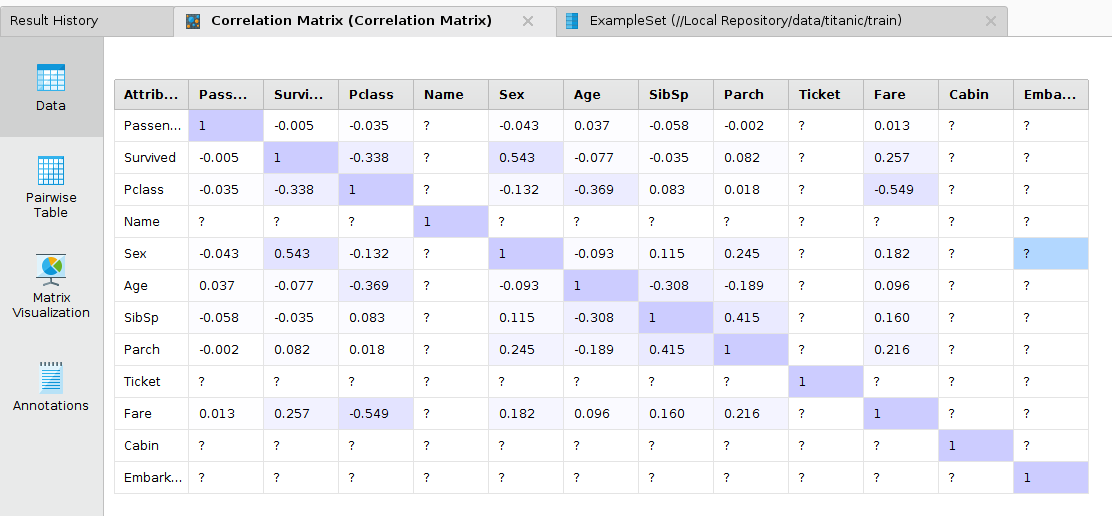
We will use the attributes: Pclass, Sex, Fare and Age (even though it is not highly correlated, binning may achieve better correlation)
Cross validation
Cross validation allows us to reserve a portion of the training dataset and use it to evaluate the model’s performance. Firstly, we need to filter out only the attributes we’re interested in, discretise and bin the Age attribute, then set the role for Survived to be a label:
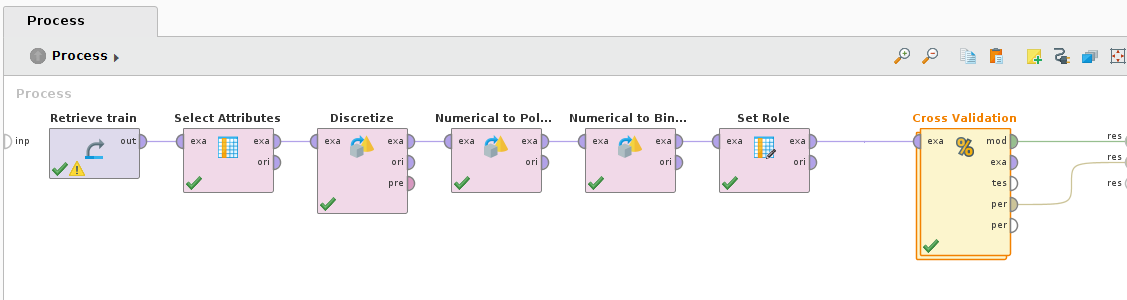 Set each operator’s parameters:
Set each operator’s parameters:
- Select Attribute - attribute filter type: subset, attributes: Age, Fare, Pclass, Sex, Survived
- Discretize by Binning - attribute filter type: single, attribute: Age, number of bins: 3
- Numerical to Polynominal - attribute filter type: single, attribute: Pclass
- Numberical to Binominal - attribute filter type: single, attribute: Survived
- Set Role - attribute name: Survived, target role: label
Much of the above could be performed on the dataset itself in the repository, but for demonstrative purposes, we’ve done it via operators. For the cross validation operator set the operator’s process by double clicking the cross validation box and cross validation process to be the following:

Click the play button and in the results view you can see the cross validation results:

Prediction Generation
We’ll now remove the cross validation operator and add the decision tree and apply model operator:
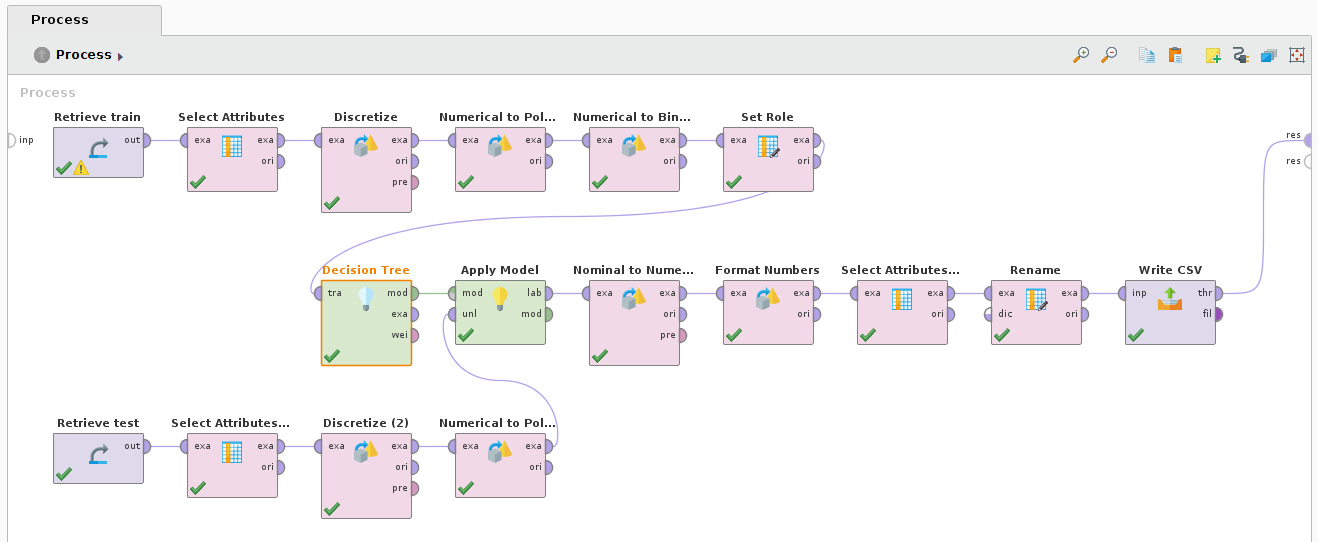
Import the test dataset with default values. Add the test dataset to the process view. Then copy the Select Attribute, Discritize and Numerical to Binominal from the training set operators. Modified the copied operator:
- Select Attributes - Add PassengerId to the attribute list
Link the “exa” output node from Numerical to Polynominal (2) to the “uni” input node of the Apply Model operator
Add the following operators to the output of the Apply Model operator:
- Nominal to Numeric - attribute filter type: single, attribute: prediction(Survived), include special attributes: checked
- Format Numbers - attribute filter type: single, attribute: prediction(Survived), include special attributes: checked, format type: integer
- Select Attributes - attribute filter type: subset, attributes: prediction(Survived), PassengerId
- Rename - old name: prediction(Survived), new name: Survived
- Write CSV - csv file: /path/to/file.csv
Once you have wired up all the operators, click the play button
Kaggle Submission
Upload the titanic predictions to Kaggle via the Submit Predictions button on the Titanic competition page. Once uploaded a submission score of 0.77511 should be achieved.